
AI-Driven Physicochemical Property Prediction for Regulated Industries
Enhance your decision-making, optimize workflows, and get robust, data-driven predictions for pKa, solubility, logP/D, and chromatographic retention times


Features & Benefits
You didn’t come this far to stop
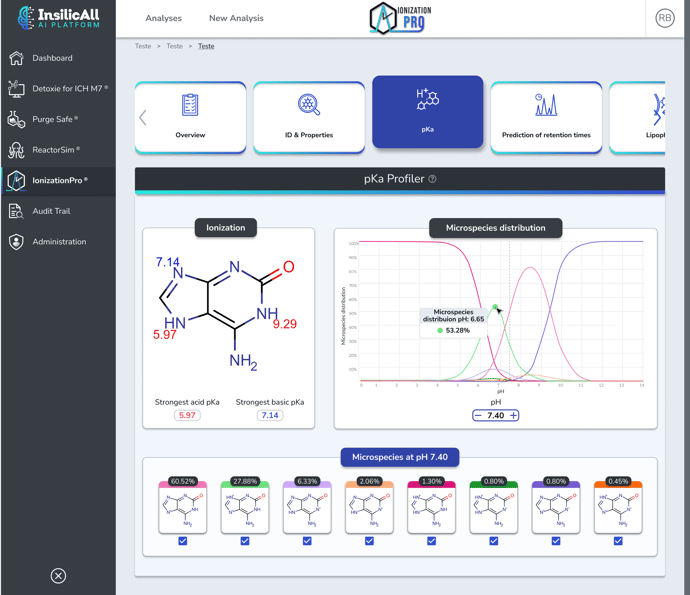
Accurate prediction of pKa and along with pH dependent distribution plots of relevant microspecies in aqueous solutions
Accelerate LC method development with highly accurate retention time prediction across six diverse chromatographic conditions
Leverage our database of >300,000 molecules—sourced from patents, literature, and pharmacopoeias—to build a powerful weight of evidence for new compounds
Calculation of partition coefficients (logP) and distribution coefficients (logD) as a function of pH to assess compound behavior in biological systems
Accurate solubility prediction in aqueous and organic solvents to accelerate your formulation, optimization, and crystallization studies
Generate regulatory reports. Guaranteed adherence to 21 CFR Part 11 & ANVISA RDC 658/2021
pKa Profiler
You know how critical an accurate pKa value is. It can be the difference between a successful drug formulation, an optimized reaction, or a dead end. Wasting time and resources on experiments guided by unreliable predictions is frustrating. We believe you deserve a better, more confident way to move forward.
1. We start with the right foundation: We use the GFN2-xTB quantum mechanical method to find the most stable tautomer of your molecule, ensuring every prediction starts from the most chemically relevant structure
2. We intelligently find the reaction sites: A Graph Neural Network (GNN), trained on a vast dataset, analyzes your molecule to identify all potential protonation and deprotonation sites—capturing complex interactions that simple rules can miss
3. We predict with enhanced accuracy: A second, powerful GNN predicts the final micro-pKa value for each site. This advanced model is uniquely enriched with QM features and fine-tuned with transfer learning on experimental data, a technique that dramatically improves its accuracy
Our pKa Profiler was engineered to give you a decisive edge. The science behind our platform delivers a new level of accuracy, with root-mean-square errors (RMSEs) between 0.5 and 0.8 pKa units on multiple benchmark datasets. This isn't just a small improvement; it's a proven methodology that significantly outperforms other well-known prediction models, allowing you to trust the data that guides your research.
What does this mean for you? It means you can spend less time repeating uncertain lab work and more time making discoveries. It means you can build stronger hypotheses, prioritize your resources effectively, and accelerate your project timelines with a greater degree of confidence.
Predict with Confidence, Powered by AI and Quantum Chemistry
Subscribe to our newsletter

InsilicAll is a leading biotech company dedicated to revolutionizing the drug discovery process. With cutting-edge technology and a team of experts, we strive to create innovative solutions for better health outcomes. Join us on our mission to make a difference in the world of biotech